서론
지난 글과 지지난 글을 통해 자동매매의 기본적인 틀을 잡았다면, 최적화하는 옵티마이저를 만들어보고자 한다.
Scheduler (Celery Beat): 주기적으로 작업을 트리거Redis: 메시지 브로커Collector: 시세(분봉) 데이터를 수집하여 DB에 적재Trader: 전략에 따라 매수/매도 시그널을 실행- Optimizer : 전략 파라미터(가중치 등)를 백테스트하여 최적화
Database (TimescaleDB): 시계열 데이터 저장소
원래는 서버 세팅 글부터 쓰려했는데 주문한 모델이 잘못 배송돼서 교환 중이다.
그래서 미뤄두었던 자동매매 봇 개발을 우선 마무리지으려고 한다.
참고로 누가 볼 진 모르겠으나, 현재까지 개발된 코드는 아래 깃허브에서 확인할 수 있다.
본론
최적화(Optimizer) 봇 구현
최적화 봇을 구현하기에 앞서 결정해야 할 것은 '무엇을' 최적화할지다.
나는 크게 두 가지를 최적화하기로 정했다.
- 전략별 가중치(Weights)
- 매매 임계값(Thresholds)
사실 가중치만 최적화하려 하였는데, 테스트해 보니 결과가 안 좋아서 급하게 추가했다.
상기 두 가지를 테스트하기 위해 백테스트용 후보군(Grid)을 만들어줬다.
STRATEGY_KEYS = [
"trend",
"momentum",
"swing",
"scalping",
"day",
"price_action",
]
def _generate_threshold_candidates():
raw = get_env("OPT_THRESHOLDS", "").strip()
if raw:
return [float(x) for x in raw.split(",") if x.strip()]
return [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5]
def _generate_weight_grid(step):
try:
step = float(step)
except Exception:
step = 0.1
if step <= 0 or step > 1:
step = 0.1
units = int(round(1.0 / step))
# 6개 전략에 대한 비음수 정수 해를 모두 생성하여 합이 units가 되도록 분배
candidates = []
for a in range(units + 1):
rem_a = units - a
for b in range(rem_a + 1):
rem_b = rem_a - b
for c in range(rem_b + 1):
rem_c = rem_b - c
for d in range(rem_c + 1):
rem_d = rem_c - d
for e in range(rem_d + 1):
f = rem_d - e
weights = [a, b, c, d, e, f]
w = [float(x) / float(units) for x in weights]
candidates.append({k: v for k, v in zip(STRATEGY_KEYS, w)})
return candidates해당 그리드를 기반으로 실제 백테스트를 아래 코드를 통해 수행하였다.
def _backtest(
closes,
weights,
threshold,
initial_cash,
fee_rate,
fee_buffer,
aggressiveness,
window=200,
):
cash_krw = float(initial_cash)
coin_qty = 0.0
equity_curve = []
returns = []
last_equity = cash_krw
win_trades = 0
total_trades = 0
min_order_krw = 5000.0
window = max(3, min(int(window), len(closes)))
for i in range(len(closes)):
price = float(closes[i])
# 매 시점의 평가금액 기록
equity = cash_krw + coin_qty * price
equity_curve.append(equity)
if i > 0 and last_equity > 0:
returns.append((equity - last_equity) / last_equity)
last_equity = equity
# 전략 계산에 필요한 최소 캔들 수 확보 후 진행
if i + 1 < max(3, window):
continue
# 최근 window개의 캔들로 시그널 계산 (현재 시점 포함)
recent = closes[i + 1 - window : i + 1]
score = float(ensemble_signal(recent, weights))
# BUY
if score >= threshold:
if cash_krw > min_order_krw:
target_price = round_price_to_tick(
price * (1.0 + aggressiveness), mode="up"
)
effective_unit_cost = target_price * (1.0 + fee_rate + fee_buffer)
if effective_unit_cost > 0:
raw_volume = cash_krw / effective_unit_cost
volume = float(np.floor(raw_volume * 1e8) / 1e8)
else:
volume = 0.0
if volume > 0 and target_price * volume > min_order_krw:
spend = target_price * volume
fee = spend * fee_rate
cash_krw -= spend + fee
coin_qty += volume
total_trades += 1
# SELL
elif score <= -threshold:
if coin_qty > 0:
target_price = round_price_to_tick(
price * (1.0 - aggressiveness), mode="down"
)
proceed = target_price * coin_qty
if proceed > min_order_krw:
fee = proceed * fee_rate
cash_krw += proceed - fee
after_equity = cash_krw
if after_equity > equity:
win_trades += 1
coin_qty = 0.0
total_trades += 1
final_equity = cash_krw + coin_qty * float(closes[-1])
total_return = (final_equity / float(initial_cash)) - 1.0
max_dd = _max_drawdown(equity_curve)
sharpe = _sharpe_ratio(returns)
win_rate = (win_trades / total_trades) if total_trades > 0 else 0.0
return {
"final_equity": final_equity,
"total_return": total_return,
"max_drawdown": max_dd,
"sharpe": sharpe,
"win_rate": win_rate,
"num_trades": total_trades,
}성능 개선
위와 같은 로직은 문제가 없어 보이지만, 실행해 보면 문제점을 하나 발견할 수 있다. 연산량이 너무 많다.
물론 못 돌릴 건 아니지만, 좀 심하게 비효율적이긴 하다.
사실 그리드 서치 자체가 비효율적이긴 하지만 그건 일단 넘어가자
너무 과한 공수는 들이기 싫어서 적당한 수준까지만 최적화를 진행해보고자 한다.
멀티 프로세싱(Multi Processing)
이때 흔히 떠올리는 방법 중 하나가 멀티 프로세싱(multiprocessing)이다.
여기서 유의해야 할 점은 Celery Worker는 기본적으로 멀티 프로세싱을 기반으로 한다. Celery Worker는 내부적으로 prefork 모델을 기본으로 사용하며, 워커를 띄울 때 가용 CPU 수만큼 프로세스를 여러 개 fork 한다.
'--concurrency', '-c' 옵션을 통해 프로세스 수를 수동으로 조정할 수도 있다.
celery -A bot.tasks worker --loglevel=INFO -Q optimizer_queue -c 4
다만 태스크를 나눠 처리한다는 것이 '하나의' 태스크를 여러 워커들이 병렬로 처리하는 게 아니다. 큐에 적재된 작업들을 각 프로세스들이 분배하는 태스크 단위 병렬 처리이지, 단일 태스크를 병렬 분할하지 않는다
보다 자세한 내용을 살펴보고 싶다면 관련 글을 읽어보면 좋을 듯하다.
사실 직접 Celery 코드 구현체를 분석해서 살펴보고 싶었으나, 너무 복잡해서 중간에 포기했다.
이러한 특징으로 인해서 Celery Worker 내부에서 추가적으로 multiprocessing을 적용하는 건 불가능하다.
보다 정확히 말하면, prefork pool일 경우엔 불가능하다.
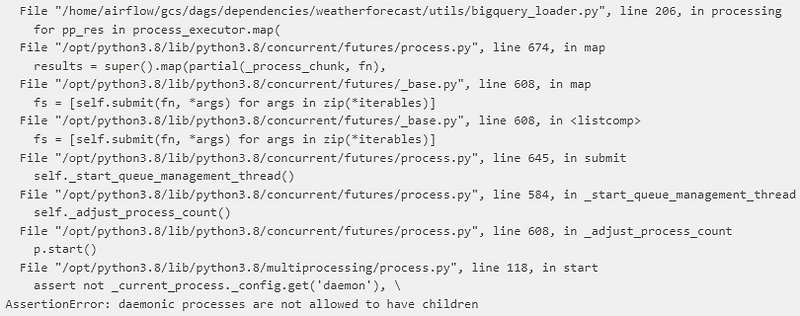
강제로 시도할 경우 아래와 같은 에러 메시지를 확인할 수 있다.
File "/usr/local/lib/python3.11/concurrent/futures/process.py", line 809, in submit
self._start_executor_manager_thread()
File "/usr/local/lib/python3.11/concurrent/futures/process.py", line 748, in _start_executor_manager_thread
self._launch_processes()
File "/usr/local/lib/python3.11/concurrent/futures/process.py", line 775, in _launch_processes
self._spawn_process()
File "/usr/local/lib/python3.11/concurrent/futures/process.py", line 785, in _spawn_process
p.start()
File "/usr/local/lib/python3.11/multiprocessing/process.py", line 118, in start
assert not _current_process._config.get('daemon'), \
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: daemonic processes are not allowed to have children이와 관련해서 자료를 찾아보니 꽤 흥미로운 내용을 알 수 있었다.
왜 멀티 프로세싱이 불가능한가
Python의 multiprocessing 공식 문서엔 아래와 같이 언급되어 있다.
출처 | multiprocessing — Process-based parallelism
보다 구체적으로 살펴보자.
Python의 multiprocessing은 기본적으로 새로운 프로세스를 만들면, 부모 프로세스의 자식으로 실행된다. 하지만 자식 프로세스가 데몬(Daemon) 프로세스인 경우에는 또 다른 자식 프로세스를 만들 수 없다고 한다.
이유인즉슨 데몬 프로세스의 부모 프로세스가 종료되면 강제 종료되는 특징으로 인해, 만약 데몬의 자식 프로세스가 남아있다면 고아 프로스세스가 되어 시스템 리소스를 점유할 수 있기 때문이다.
여기서 조금 혼동이 왔는데, 필자가 기존 알고 있던 데몬 프로세스라 함은 OS 부팅 시 자동으로 실행되며, 부모 프로세스와 무관하게 계속해서 동작한다고 알고 있었다.
하지만 위에 설명된 내용을 보면 필자가 알고 있는 내용과 정반대의 내용이어서 찾아보니, Python에서 multiprocessing.Process(daemon=True)는 단순히 부모 프로세스가 종료될 때 자동으로 종료됨을 의미한다.
즉, UNIX 운영체제에서의 데몬 프로세스와 Python의 데몬 프로세스는 그 의미가 다르다는 것이다.
마찬가지로 공식 문서를 살펴보니 실제로 아래와 같은 설명이 명시되어 있음을 확인할 수 있었다.
"When a process exits, it attempts to terminate all of its daemonic child processes."
출처 | multiprocessing — Process-based parallelism
그럼 여기서 의문점이 한 가지 생긴다. 왜 Celery Worker는 데몬 프로세스라고 하는 것일까?
앞서 언급하였듯이 Celery의 prefork 방식은 기본적으로 가용 CPU 수만큼 프로세스를 fork 한다. 이 과정에서 billiard라는 multiprocessing을 fork 한 라이브러리를 사용하는데, 해당 라이브러리는 Pool Worker를 만들 때 내부적으로 해당 프로세스들을 데몬 프로세스로 지정한다.
# billiard/pool.py line 1139
class Pool:
'''
Class which supports an async version of applying functions to arguments.
'''
...
def _create_worker_process(self, i):
sentinel = self._ctx.Event() if self.allow_restart else None
inq, outq, synq = self.get_process_queues()
on_ready_counter = self._ctx.Value('i')
w = self.WorkerProcess(self.Worker(
inq, outq, synq, self._initializer, self._initargs,
self._maxtasksperchild, sentinel, self._on_process_exit,
# Need to handle all signals if using the ipc semaphore,
# to make sure the semaphore is released.
sigprotection=self.threads,
wrap_exception=self._wrap_exception,
max_memory_per_child=self._max_memory_per_child,
on_ready_counter=on_ready_counter,
))
self._pool.append(w)
self._process_register_queues(w, (inq, outq, synq))
w.name = w.name.replace('Process', 'PoolWorker')
# ===================
w.daemon = True
# ===================
w.index = i
w.start()
self._poolctrl[w.pid] = sentinel
self._on_ready_counters[w.pid] = on_ready_counter
if self.on_process_up:
self.on_process_up(w)
return w정리해 보자면 Celery init 스크립트가 실제 작업 수행을 위한 Worker를 생성하는 과정에서, 각 Worker들이 데몬 프로세스로 생성됨으로 인해 Worker 내부에서 추가 멀티 프로세싱이 불가능해지는 것이다.
다시 한번 말하지만 Python에서의 데몬 프로세스는 UNIX의 데몬 프로세스와 다름을 염두해야 한다.
멀티 스레딩(Multi Threading)
Celery 옵션에서 Prefork가 아닌 '--pool=threads'를 주면 스레드 기반으로 태스크를 실행할 수도 있다. 하지만 마찬가지로 태스크 단위 병렬 처리이지, 단일 태스크를 병렬 분할이 아니다.
간단한 자동매매 봇 개발기에서 생각보다 먼 길을 돌아오긴 했지만, 결국 알게 된 사실은 Celery에서 제공하는 '--pool' 옵션으로는 내가 원하는 단일 작업 병렬 처리가 불가능하다는 것이다. 이로 인해 그냥 심플하게 optimizer.py 내부에서 직접 ThreadPool을 만들어 병렬로 처리하고자 한다.
굉장히 먼 길을 돌아온 것치곤 다소 허무한 결말이다.
pairs = []
def _eval_one(p):
return (
_backtest(
closes=closes,
weights=p["weights"],
threshold=p["threshold"],
initial_cash=initial_cash,
fee_rate=fee_rate,
fee_buffer=fee_buffer,
aggressiveness=aggressiveness,
window=opt_window,
),
p,
)
max_workers = int(get_env("OPT_THREADS", str(min(8, (os.cpu_count() or 4)))))
with ThreadPoolExecutor(max_workers=max_workers) as executor:
for res in executor.map(_eval_one, param_list, chunksize=1):
pairs.append(res)이렇게 적용하고 백테스트를 다시 실행하면 실제 성능 개선이 있을까?
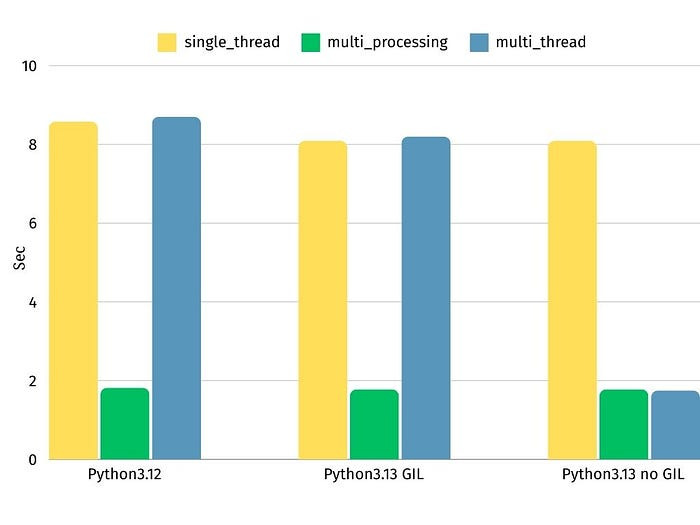
아쉽게도 기대한 만큼의 성능 개선이 이루어지진 않았다.
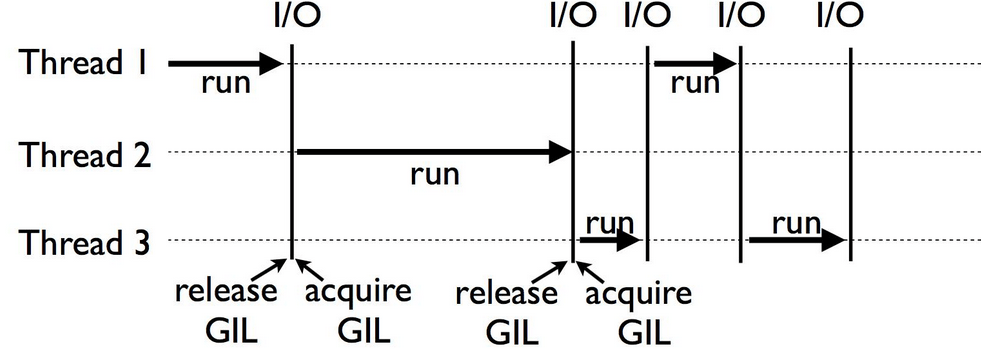
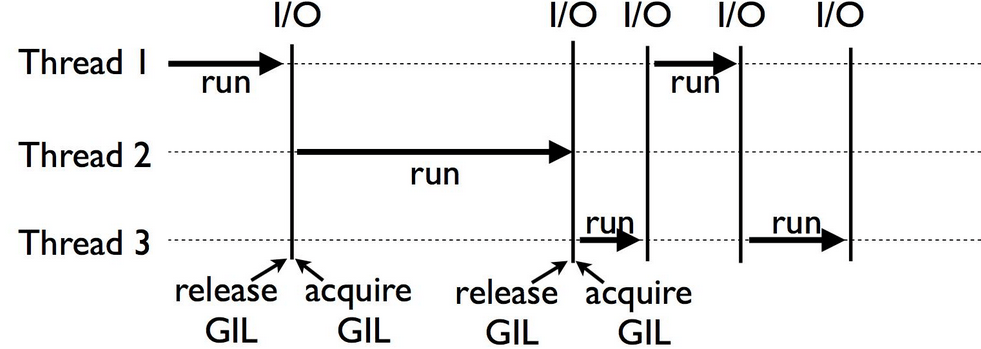
Python의 GIL(Global Interpreter Lock)
Python에 대해 잘 아는 사람들이라면, 아마 멀티 스레딩 얘기가 나왔을 때부터 눈치챘을 것 같다.
Python에는 떼려야 뗄 수 없는 악연이 존재하는데, 바로 GIL(Global Interpreter Lock)이다. GIL로 인해 멀티 스레딩은 진짜 병렬이 아니라, 한 시점에 하나의 스레드만 실행된다.
본 글에서 해당 내용까지 다루기엔 무리가 있을 것 같아 궁금한 사람은 아래 글을 읽어보면 좋을 듯하다.
어쨌든 관련 자료를 찾아보던 중, Python 3.13부터는 GIL을 해제할 수 있는 기능이 존재한다고 하여 진행해 봤다.
GIL을 해제하기 위해선 일반 3.13 버전의 파이썬이 아닌 테스트 버전을 필요로 한다. 뭔가 복잡해 보이는 빌드 과정을 거쳐야 하던데 그런 건 잘 모르겠고, 누가 GIL 해제한 버전의 도커 이미지를 올려뒀기에 그걸로 베이스 이미지를 변경했다.
이에 맞춰 라이브러리 버전도 업데이트해 주고 빌드해 보니 정상적으로 GIL이 비활성화된 걸 확인할 수 있었다.
Python 3.13.1 experimental free-threading build (main, Jan 14 2025, 22:37:55) [GCC 6.3.0 20170516] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> print(sys._is_gil_enabled())
False이후 백테스트 코드를 다시 수행해 보면 정상적으로 단일 워커 내에서 멀티 스레드로 동작하는 걸 확인할 수 있다.


사실 직접 백테스트 수행한 뒤 실제 시간을 비교해보고 싶었으나, 현재 개발 진행 중인 노트북은 계속 껐다 켰다 하느라 정확한 시간 측정이 안 돼서 정확한 시간 비교를 하지 못하였다.
그럼에도 불구하고 간단히 백테스트 결과만 공유해 보자면, 3개월 데이터를 돌렸을 때 흑자가 발생하는 조합이 없었다. 이전 간단한 백테스트 코드에서 이상하게 흑자가 날 때부터 예상하긴 했으나, 다소 씁쓸한 결과이긴 하다.
결론
이번 글까지 해서 자동매매 봇 개발기가 어느 정도 마무리되었다. 단순 자동매매 봇 개발기를 작성하려고 한 건데, 생각보다 이것저것 내용들이 많이 욱여넣어진 것 같다.
물론 성능 개선은 위에서 언급한 내용들 뿐 아니라 더 할 수도 있다.
- Grid Search 탐색 방식 개선
- 시그널 사전계산 (NumPy 벡터화)
하지만 해당 기능까지 개발하기엔 너무 과한 것 같아 이 정도 수준에서 마무리하고자 한다. 추후 시간 여유가 더 된다면 재미 삼아해보지 않을까 싶다.
서버가 오면 한 달 정도 굴려본 뒤 결과를 공유해 보겠다.
참고자료